

|
|
PageBox |
|
| Rationale | Presentation | News | Faq | Authors | Dev site | Mailing list |
Last month, we looked at the advantages of downloading servlets and Java Server Pages (JSP) from a repository, like a browser downloads applets. Was described a simple implementation of this concept, based on a service servlet and on a custom class loader. This tool, named JSPservlet handled servlets and JSP packaged in jar archives to minimize the number of connections and transfers required.
This month, I will show you how to publish an archive, update it or force its download through a JSPupdate servlet and how to extend the solution in order to handle resources, HTTP caching, request forwarding, page inclusion, JSP beans.
This simple JSP, JSPupdate handles archive publishing and update.
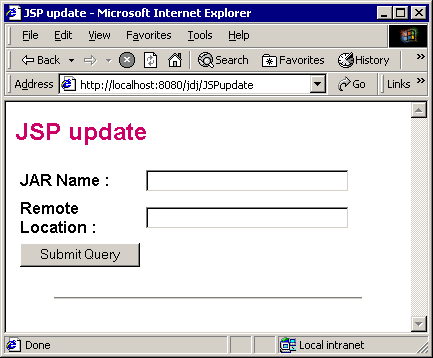
Figure 1: JSPupdate display
JSPservlet and JSPupdate are packaged in a Web Application, so typically in a war archive described by a web.xml deployment descriptor as shown in Listing 0. This archive is a general-purpose agent responsible to download the target presentation archives and to route requests to their servlets and JSPs.
Publishing a new archive implies querying the proper agent and providing the archive name and the remote location where it must be downloaded from. Practically, you simply identify the agent on your browser by its URL, in this example http://localhost:8080/jdj/JSPupdate where http://localhost:8080 identifies the Java Server and jdj the agent’s Web Application itself. You are displayed the Figure 1 form, you fill it and click the button to start the publishing. You use the same form to change the archive location or to force a new download. In this latter case, you don’t even need to fill the remote location.
Lets go back to the tool design to walk through the implementation of JSPupdate.
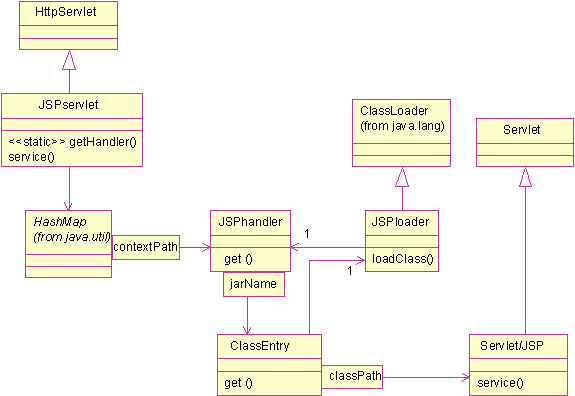
Figure 2: Tool class diagram
A special servlet, JSPservlet handles HTTP requests toward a Web Application and forwards them to target servlets and JSPs with the help of a set of objects:
1. JSPhandler objects manage Web Applications and maintain a ClassEntry map
2. ClassEntry objects manage archives and maintain a cache of target objects
3. JSPloader objects are target servlets class loaders and maintain a cache of target classes
Therefore JSPupdate handling implies the following steps:
1. Identifying the relevant JSPhandler, creating it on the fly if it doesn’t exist
2. Finding the ClassEntry responsible of the archive
3. If it is doesn’t exist yet, creating a ClassEntry. In this case, the tool acts as an archive publisher.
4. Otherwise, unreferencing the JSPloader and clearing the target object cache. Instantiating a new JSPloader.
The first step is implemented in JSPupdate and JSPhandler. Listing 1 shows the JSPupdate code. I preferred GET mode to simplify update by programs or scripts. I will come back on this point in next section. In the script, starting on line 27, I get first the JAR name you filled on the form and the Application name, contextPath from the URL. Then I look for the corresponding JSPhandler in the JSPhandlers HashMap and finally I invoke the JSPhandler’s update() method. I postpone to the RequestDispatcher section the explanation of the case where the appropriate JSPhander doesn’t exist.
Listing 2 shows the JSPhandler.update() implementation. Remember the tool minimizes downloads from a central repository and handles its unavailability thanks to a local archive copy. JSPhandler.update() first removes this archive cache with File.delete(). Then if you filled the Remote Location field, it updates the remoteLocProp property and persists it on remoteLocFile. Eventually, JSPhandler.update() looks for the appropriate ClassEntry in classEntries HashMap and invokes its update() method. If it does not find it, it creates a new ClassEntry and adds it to classEntries.
Listing 3 shows the ClassEntry.update() implementation. It first invokes the destroy() method of all cached target objects. Then it clears the target objects HashMap, servletObjects to unreference them and unreferences the corresponding JSPloader instance. Next ClassEntry.update() invokes the garbage collector, which can free the target and JSPloader objects and also the target classes and static data. Though the garbage collection can take time, it reduces the Java Server footprint and improves its behavior. I considered the garbage collection duration as a minor drawback as I designed JSPupdate to be invoked outside peak hours. Once the Java Virtual Machine (JVM) got the opportunity to reclaim the memory occupied on behalf of the archive, ClassEntry.update() creates a new JSPloader and a new target object cache.
JSPupdate uses the GET mode. So to require the update of an application whose URL is http://www.iamakishirofan.com/gunnm for a JAR named gally stored in a repository located in http://myserver, you simply need to use the URL:
http://www.iamalishirofan.com/gunnm/JSPupdate?jarName=gally&remoteLocation=http%3A%2F%2F myserver&Submit=JSPupdate
Listing 4 shows a Java class, UpdateClient you can use to update an archive from the command line or from a script. To update the application above, you invoke UpdateClient either with:
java JSPservletPkg/UpdateClient http://www.iamalishirofan.com/gunnm gally http://myserver if you want to publish or update the remote location or with:
java JSPservletPkg/UpdateClient http://www.iamalishirofan.com/gunnm gally if you simply need to force a download.
UpdateClient first builds a URL string with UpdateClient’s parameters. To convert the remote location to a MIME format appropriate in a URL, UpdateClient simply uses URLEncoder.encode(). Then it creates an URL, open and read a stream, which it parses to check the Java Server response. You can use the exit code in your script to handle error cases, the most common being the Server unavailability.
Consider the common case where a Java Server Page (JSP) or a servlet refers to an image with a URL relative to the current path. Since JSPservlet is configured in the Web Application deployment descriptor to handle all its requests, it has also to process image requests. This case raises three issues, first how to detect an image request, second where to download the image from and third where to handle the request.
I chose to delegate images and other resources handling to JSPloader because, as we will see later in Beans section, it has anyway to address other resource needs.
Where to download the resources from? Should we cache them? These issues are not trivial, as an image is much larger than a JSP or servlet. My choice is to support resources included in the archive file or stored in the same remote location as the archive and to cache resources in memory.
Listing 5 shows the resource handling in JSPservlet. JSPservlet detects images and other resource like html files after their URL extension. It sets also the content type according to the URL extension. Then it uses JSPhandler.getResourceAsStream() to get an input stream on the resource from JSPloader. JSPhandler simply forwards the request to the appropriate ClassEntry which invokes JSPloader.getResourceAsStream(). If getResourceAsStream() doesn’t find the resource, JSPservlet invokes HttpServletResponse.sendError(SC_NOT_FOUND), which builds a HTTP response with a 404 status, indicating that the requested resource is not available. Otherwise JSPservlet reads the input stream and rewrites it on the response output stream.
In order to support resources embedded in archive, I modified last month JSPloader.ParseStream() method. Remember this method is invoked at JSPloader construction to parse the archive content read either from the local archive cache or from its remote location. In the latter case, it is also responsible to store the archive in the local cache. The modification is however minimal as you can see on Listing 6. JSPloader maintains a resources HashMap, which acts as a resource memory cache like classes acts as a class memory cache. parseStream stores a resource in a byte array in resources, instead storing a class in classes.
Listing 7 shows the JSPloader.getResourceAsStream() implementation. It first tries to retrieve the resource from the resources memory cache. If it doesn’t find it, it tries to download the resource from the same location as the archive with URL(remoteLoc).openStream(). Then it stores it in resources. So, if a resource is stored in the archive, it is always served from resources and a resource that must be downloaded is downloaded only once and then served from resources. If the resource is neither in the archive, nor remotely available, getResourceAsStream() delegates the request to getResourceForward() in order to support local Java Server resources. getResourceForward() tries first to get the resource using the getResourceAsStream() method of JSPservlet’s class loader, to find it in JSPservlet’s Web Application and then using the getResourceAsStream() method of JSPloader parent class loader to find it elsewhere.
Figure 3 displays a typical HTTP caching scenario with three actor types, browsers, a proxy and an HTTP server. A first browser requires a URL the proxy doesn’t find in its cache. So it requests the URL to the HTTP server with an HTTP GET. The HTTP server returns a response, which includes also Expires, ETag and Last-Modified header fields. The Expires field gives the date/time after which the response is considered stale, the ETag field provides a Entity tag value which can be used for comparisons and the Last-Modified tag indicates the date and time at which the server believes the data was last modified.
The proxy stores the response in cache and returns it to the browser. Then a second browser requires the same URL. The proxy finds the response is not staled so it returns it to the browser without requesting the HTTP Server. Next a third browser requires the same URL again, this time the response is staled but still in cache, so the proxy asks the HTTP server if the response is still valid with a conditional HTTP GET (a GET with a field If-None-Match or If-Modified-Since). The HTTP server checks if the Entity tag is the same in case of If-None-Match or if the Last-Modified tag has not changed in case of If-Modified-Since. If yes, it sends a Not Modified response without a body. If the browser requested an image, the image is not transferred, if it requested a dynamic page, which required RDBMS access or heavy computation, this processing is not needed.
The HTTP server sends an updated Expires value in its Not Modified response, so if a fourth browser requests the same URL before the updated date/time, the proxy will again serve the response without involving the HTTP server.
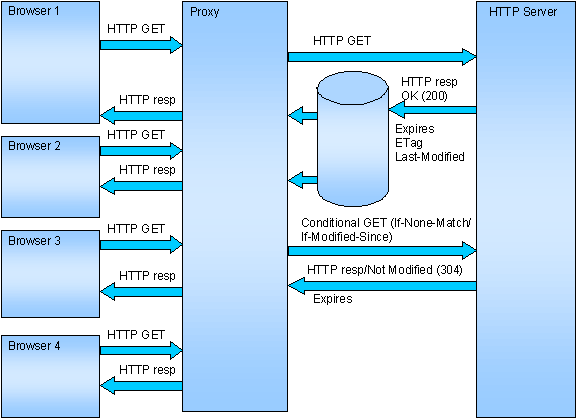
Figure 3: Caching mechanisms
I described the behavior of a proxy for clarity but a browser caches also the responses it receives and behaves exactly the same way regarding the header fields presented on Figure 3. It is the reason I had to involve four different browsers in the scenario. As a consequence, an HTTP server can drive both proxy and browser caching with the same code.
To implement that mechanism for resource requests, I had to take two decisions:
1. Where should I take the Last-Modified date/time?
2. Should I implement Expire?
Remember JSPloader.getResourceAsStream() implementation. It tries to retrieve the resource first from the archive, then from the same location as the archive and eventually by asking the Java Server class loader. When the resource is stored in the archive, it picks up the Last-Modified date/time from the archive entry with JarEntry.getTime(). When the resource is stored in the same location as the archive, it uses a URLConnection object to download it. URLConnection acts as a browser, so it has access to HTTP headers. It even provides helper methods for the most common headers like URLConnection.getLastModified() for Last-Modified that JSPloader.getResourceAsStream() invokes. In the last case, where JSPloader.getResourceAsStream() asks to the Java Server for the resource, I use the archive cache creation time. The rationale is this sort of resource is typically stored on Java Server and therefore cheap to retrieve.
On the bottom line, it means that:
1. If an archive or downloaded resource has not changed, JSPservlet will return Not Modified even after an archive update.
2. For a resource retrieved by the Java Server class loader, JSPservlet will return a full response at the first request after an archive update.
When the proxy receives a response containing ETag or Last-Modified, it can set an internal Expiration value. However this behavior is not mandatory and can vary, so I preferred to implement Expire and let you set it in an additional initialization parameter, expiration, whose default is five seconds. HTTP 1.1 specification allows you to go up to one year but its optimal value depends on your configuration. Higher it is, more time it will take to refresh caches after an update and if your browsers are on the same LAN as the Java Server, you don’t really need to care about round trip delays.
Let’s go back to Listing 5 to look at the implementation details.
JSPservlet checks if the HTTP request was conditional. More precisely it retrieves the value of ifNoneMatch and ifModified header fields. If they are set, it checks respectively if client Entity tag and Last modified date/time are still the same as server ones. If they are, JSPservlet returns an HTTP response with a status Not Modified (303), using HttpServletResponse.sendError(SC_NOT_MODIFIED). This response includes an Expires field set with:
HttpServletResponse.setDateHeader("Expires", System.currentTimeMillis() + jh.expiration * 1000).
setDateHeader is another convenient helper method that simplifies setting a date header field. It takes two parameters, the name of the field and the elapsed time since the epoch (January first, 1970). JSPhandler computes it using JSPhandler’s expiration, which contains the expiration initialization parameter.
If either the HTTP request was not conditional or if cache entries are staled, JSPservlet sends the resource. It sets before Date, Cache-control, Last-Modified, ETag and Expires header fields. Date represents the date and time, at which the message is originated. JSPservlet builds it like Expires. Cache-control:public indicates the response may be cached by any cache. I already covered Last-Modified and ETag. Both contain the date and time extracted by JSPloader. Last-Modified handling is slightly more complex as JSPservlet formats it in RFC 1123 format – the HTTP preferred date format – using a java.text.SimpleDateFormat.
When building a Web Application, it is common to forward processing of a request to another servlet, or to include the output of another servlet in the response. Servlet specification defines RequestDispatcher interface to accomplish this. The support of this feature implies some modifications in JSPservlet code.
First let’s look why and how JSPservlet is involved. You get a RequestDispatcher from the Context, you can see as an interface to the Web Application. RequestDispatcher allows forwarding to another servlet or including the output of a servlet, defined in the same Web Application. As JSPservlet handles all requests toward a Web Application, it is invoked.
The first issue is related to include specification. The included servlet has access to the including servlet’s request object. So when JSPservlet is invoked on behalf of an included servlet, the request path doesn’t contain its path but the path of the servlet, which included it. It is annoying as JSPservlet uses the path to identify the archive and the class to forward the request to. Fortunately it is possible to know the path by which a servlet was invoked thank to special request attributes described by Java™ Servlet Specification, v2.2. For instance, I can get the included servlet pathInfo, whose I extract the archive and servlet names with:
String pathInfo = (String)request.getAttribute("javax.servlet.include.path_info").
If the attribute is not defined, it means the servlet was not included, so I can safely retrieve pathInfo with request.getPathInfo().
A bigger issue is related to context root. You can get a RequestDispatcher with
ServletContext.getRequestDispatcher("/garden/header.html"). The "/garden/header.html" path is relative to the root of the Web Application, which doesn’t contain the archive name. So JSPservlet will not be able to handle the request. There are two solutions to this problem. The fully standard one is to use relative paths with ServletRequest.getRequestDispatcher(). As we are using ServletRequest, the path can be relative to the current request. It addresses the common case where the included servlet is located at the same place as the including one. If it is not the case, you must add the archive name, for instance:
ServletContext.getRequestDispatcher(jarName + "/garden/header.html").
The drawback of this solution is it breaks the independence between development and deployment (where archive names are chosen). I provide in the complete implementation a JSPhandler.getJAR(ServletRequest) static method to return the current archive name. Note you can use it without breaking your servlet portability if you use reflection as shown on Listing 8.
I considered and rejected a fully transparent method. Remember the including servlet is invoked through JSPservlet. So I could implement a special ServletContext delegating all calls to the JSPservlet ServletContext but getRequestDispatcher() where I would transparently add the current archive name. I rejected this solution as it forbid invoking a servlet hosted in a different archive. However if your requirements are different of my ones, you can implement this solution.
Now we can come back to the JSPupdate pending issue, to the update handling when the appropriate JSPhander doesn’t exist yet. The problem origin relies in JSPupdate and JSPservlet deployment descriptor (Listing 0). JSPupdate cannot be included in an archive because otherwise it would be unable to download an initial archive and JSPhandler relies on JSPservlet init-params to initialize. So JSPupdate needs to call JSPservlet when it needs to create a JSPhandler and the solution to achieve this it to use a RequestDispatcher.
Let’s revisit the JSPupdate code ( Listing 1). On line 39, you see that when the appropriate JSPhandler doesn’t exist, JSPupdate creates a RequestDispatcher with getServletContext().getRequestDispatcher("/JSPservlet") and use it to include JSPservlet.
JSPservlet.service() must be modified to include the Listing 9 code in order to identify and process updates. This code first retrieves JSPservlet context path using the javax.servlet.include.context_path attribute, as JSPservlet is included. Then it invokes getHandler(), which will create the appropriate JSPhandler. Next the implementation detects it is called through a JSPupdate include by checking the including servlet name, returned by request.getServletPath(). Eventually it retrieves the archive name and remote location from the request and invokes JSPhandler.update(), which calls ClassEntry.update().
JavaServer Pages™ Specification 1.1 provides two mechanisms to integrate Java logic, Beans and the more recent Tag Extensions. Tag Extension is arguably more sophisticated and complex. However it requires no special handling because Tag Extensions are converted to Java code at JSP compilation time. Therefore we don’t need to distribute Tag Library Descriptors and we can retrieve Tag handler classes from the archive as usual. Though Beans are simpler, they can raise an issue in the tool context.
The compiled JSP should create a Bean with Beans.instantiate(getClassLoader(), beanName). This static method allows specifying the class loader to use and its beanName can indicate either a serialized object or a class. For example, given a beanName of "x.y", Beans.instantiate would first try to read a serialized object from the resource "x/y.ser" and if that failed it would try to load the class "x.y" and create an instance of that class. So, to fully support Beans I need to allow unserializing from archives.
My code supports the Beans.instantiate(getClassLoader(), beanName) way to create the bean (Tomcat code) because target JSPs are loaded by JSPloader. Therefore getClassLoader() returns the relevant JSPloader instance, whose getResourceAsStream() is invoked to get the serialized bean.
It is not difficult to develop a solution, portable across Java Application Servers, that:
1. Dynamically downloads Web Applications from one or many repositories
2. Command downloads or updates from anywhere using a browser or a command, which can be started from a scheduling tool
3. Supports Web Applications’ JSPs and servlets, according to JavaServer Pages™ Specification, v1.1 and Java™ Servlet Specification, v2.2.
A Java Server can act as a browser that downloads applets on demand and therefore be administration-free. There is however a difference. Nothing prevents a large number of browsers to download the same applet at the same time, collapsing the network. As Java servers download only when commanded, they avoid this problem.
Rationale
Presentation News
Faq Dev site
Mailing lists Home
Installation Versions Constellations
Device Demo Mapper
Security Cocoon/SOAP Configurator
J2EE version Embedded version
Diskless version Publisher
Contact:support@pagebox.net
©2001 Alexis Grandemange
Last modified